Beschleunigung von Spread-Elementen
Während seines dreimonatigen Praktikums im V8-Team arbeitete Hai Dang daran, die Leistung von [...array], [...string], [...set], [...map.keys()] und [...map.values()] zu verbessern (wenn die Spread-Elemente am Anfang des Array-Literals stehen). Er machte auch Array.from(iterable) deutlich schneller. Dieser Artikel erklärt einige Details seiner Änderungen, die ab V8 v7.2 enthalten sind.
Spread-Elemente
Spread-Elemente sind Komponenten von Array-Literalen, die die Form ...iterable haben. Sie wurden in ES2015 eingeführt, um Arrays aus iterierbaren Objekten zu erstellen. Zum Beispiel erstellt das Array-Literal [1, ...arr, 4, ...b] ein Array, dessen erstes Element 1 ist, gefolgt von den Elementen des Arrays arr, danach 4 und schließlich die Elemente des Arrays b:
const a = [2, 3];
const b = [5, 6, 7];
const result = [1, ...a, 4, ...b];
// → [1, 2, 3, 4, 5, 6, 7]
Ein weiteres Beispiel: Jeder String kann aufgebrochen werden, um ein Array seiner Zeichen (Unicode-Codepunkte) zu erstellen:
const str = 'こんにちは';
const result = [...str];
// → ['こ', 'ん', 'に', 'ち', 'は']
Auf ähnliche Weise kann jedes Set aufgebrochen werden, um ein Array seiner Elemente zu erstellen, sortiert nach Einfügereihenfolge:
const s = new Set();
s.add('V8');
s.add('TurboFan');
const result = [...s];
// → ['V8', 'TurboFan']
Im Allgemeinen geht die Syntax der Spread-Elemente ...x in einem Array-Literal davon aus, dass x einen Iterator bereitstellt (zugänglich über x[Symbol.iterator]()). Dieser Iterator wird dann verwendet, um die in das resultierende Array einzufügenden Elemente zu erhalten.
Der einfache Anwendungsfall, ein Array arr in ein neues Array zu zerlegen, ohne vorher oder hinterher weitere Elemente hinzuzufügen, [...arr], wird in ES2015 als eine prägnante, idiomatische Methode zum flachen Klonen von arr angesehen. Leider hinkte in V8 die Leistung dieses Idioms deutlich hinter seinem ES5-Gegenstück her. Das Ziel von Hais Praktikum war es, dies zu ändern!
Warum sind (oder waren!) Spread-Elemente langsam?
Es gibt viele Möglichkeiten, ein Array arr flach zu klonen. Zum Beispiel können Sie arr.slice(), oder arr.concat(), oder [...arr] verwenden. Oder Sie können Ihre eigene clone-Funktion schreiben, die eine Standard-for-Schleife verwendet:
function clone(arr) {
// Die korrekte Anzahl von Elementen vorab zuweisen, um
// das Wachsen des Arrays zu vermeiden.
const result = new Array(arr.length);
for (let i = 0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
Idealerweise sollten alle diese Optionen ähnliche Leistungsmerkmale haben. Leider ist [...arr] in V8 (oder war) wahrscheinlich langsamer als clone! Der Grund dafür ist, dass V8 [...arr] im Wesentlichen in eine Iteration wie die folgende transpiliert:
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
Dieser Code ist im Allgemeinen aus mehreren Gründen langsamer als clone:
- Es muss der
iteratordurch Laden und Auswerten derSymbol.iterator-Eigenschaft am Anfang erstellt werden. - Es muss bei jedem Schritt das
iteratorResult-Objekt erstellt und abgefragt werden. - Es wächst das
result-Array bei jedem Iterationsschritt durch den Aufruf vonpush, wodurch der Speicher wiederholt neu zugewiesen wird.
Der Grund für diese Implementierung ist, wie bereits erwähnt, dass Spread nicht nur bei Arrays, sondern auch bei beliebigen iterierbaren Objekten erfolgen kann und dem Iterationsprotokoll folgen muss. Dennoch sollte V8 in der Lage sein zu erkennen, wenn das Objekt, das zerlegt wird, ein Array ist, sodass es die Extraktion der Elemente auf einer niedrigeren Ebene ausführen kann und damit:
- die Erstellung des Iterator-Objekts vermeiden,
- die Erstellung der Iterator-Ergebnisobjekte vermeiden, und
- das ständige Wachsen und damit die Neuverteilung des Ergebnisarrays vermeiden (wir kennen die Anzahl der Elemente im Voraus).
Diese einfache Idee haben wir mit CSA für schnelle Arrays implementiert, d.h. Arrays mit einer der sechs am häufigsten verwendeten Elementarten. Die Optimierung gilt für das häufige Szenario in der realen Welt, bei dem die Streuung am Beginn eines Array-Literals auftritt, z.B. [...foo]. Wie im untenstehenden Diagramm gezeigt, führt dieser neue schnelle Pfad zu einer Leistungsverbesserung von etwa 3× für das Zerlegen eines Arrays mit 100.000 Elementen und macht es etwa 25% schneller als die handgeschriebene clone-Schleife.
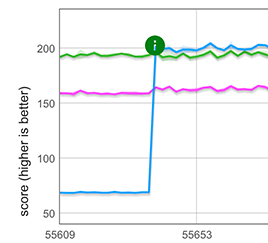
Hinweis: Obwohl hier nicht gezeigt, gilt der schnelle Pfad auch, wenn die Spread-Elemente von anderen Komponenten gefolgt werden (z.B. [...arr, 1, 2, 3]), jedoch nicht, wenn sie von anderen Komponenten vorangegangen werden (z.B. [1, 2, 3, ...arr]).
Vorsicht beim schnellen Pfad
Das ist eindeutig eine beeindruckende Geschwindigkeitssteigerung, aber wir müssen sehr vorsichtig sein, wann es korrekt ist, diesen schnellen Pfad zu wählen: JavaScript ermöglicht es Programmierern, das Iterationsverhalten von Objekten (sogar Arrays) auf verschiedene Weise zu ändern. Da Spread-Elemente so definiert sind, dass sie das Iterationsprotokoll verwenden, müssen wir sicherstellen, dass solche Änderungen respektiert werden. Dies gewährleisten wir, indem wir den schnellen Pfad vollständig vermeiden, wenn die ursprünglichen Iterationsmechanismen verändert wurden. Beispielsweise gehören folgende Situationen dazu.
Eigene Symbol.iterator-Eigenschaft
Normalerweise hat ein Array arr keine eigene Symbol.iterator-Eigenschaft, sodass beim Nachschlagen dieses Symbols es im Prototyp des Arrays gefunden wird. Im folgenden Beispiel wird der Prototyp durch die direkte Definition der Symbol.iterator-Eigenschaft auf arr selbst umgangen. Nach dieser Änderung führt das Nachschlagen von Symbol.iterator auf arr zu einem leeren Iterator, und dadurch liefert das Spread von arr keine Elemente und der Array-Literal wird zu einem leeren Array ausgewertet.
const arr = [1, 2, 3];
arr[Symbol.iterator] = function() {
return { next: function() { return { done: true }; } };
};
const result = [...arr];
// → []
Modifiziertes %ArrayIteratorPrototype%
Die Methode next kann auch direkt auf %ArrayIteratorPrototype%, dem Prototyp von Array-Iteratoren (was alle Arrays betrifft), geändert werden.
Object.getPrototypeOf([][Symbol.iterator]()).next = function() {
return { done: true };
}
const arr = [1, 2, 3];
const result = [...arr];
// → []
Umgang mit löchrigen Arrays
Besondere Vorsicht ist auch geboten, wenn Arrays mit Löchern kopiert werden, d.h. Arrays wie ['a', , 'c'], die einige Elemente fehlen. Das Ausbreiten eines solchen Arrays bewahrt die Löcher aufgrund des Iterationsprotokolls nicht, sondern ersetzt sie durch die Werte, die im Prototyp des Arrays an den entsprechenden Indizes gefunden werden. Standardmäßig gibt es keine Elemente im Prototyp eines Arrays, was bedeutet, dass alle Löcher mit undefined gefüllt werden. Zum Beispiel wird [...['a', , 'c']] zu einem neuen Array ['a', undefined, 'c'] ausgewertet.
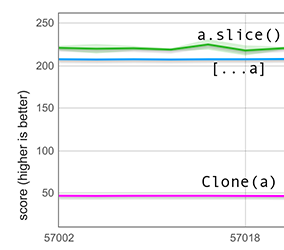
Unser schneller Pfad ist intelligent genug, um Löcher in dieser Standardeinstellung zu behandeln. Anstatt blind den Speicher des Eingabe-Arrays zu kopieren, achtet er auf Löcher und kümmert sich darum, sie in undefined-Werte zu konvertieren. Die folgende Grafik enthält Messungen für ein Eingabe-Array der Länge 100.000, das nur (markierte) 600 Ganzzahlen enthält — der Rest sind Löcher. Es zeigt, dass das Ausbreiten eines solchen löchrigen Arrays jetzt über 4× schneller ist als die Verwendung der clone-Funktion. (Früher waren sie ungefähr gleich schnell, aber dies wird in der Grafik nicht gezeigt).
Beachten Sie, dass, obwohl slice in diesem Diagramm enthalten ist, der Vergleich damit unfair ist, da slice eine andere Semantik für löchrige Arrays hat: Es bewahrt alle Löcher, sodass es viel weniger Arbeit leisten muss.
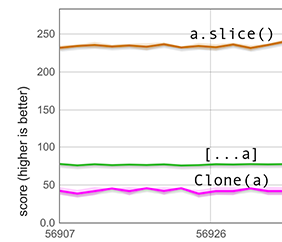
Das Füllen von Löchern mit undefined, das unser schneller Pfad durchführen muss, ist nicht so einfach, wie es klingt: Es kann erforderlich sein, das gesamte Array in eine andere Elementart zu konvertieren. Die nächste Grafik misst eine solche Situation. Der Aufbau ist derselbe wie oben, außer dass diesmal die 600 Array-Elemente unboxte Doubles sind und das Array die Elementart HOLEY_DOUBLE_ELEMENTS hat. Da diese Elementart keine markierten Werte wie undefined halten kann, beinhaltet das Ausbreiten eine kostspielige Elementart-Transition, weshalb der Wert für [...a] in der vorherigen Grafik viel niedriger ist. Dennoch ist es immer noch viel schneller als clone(a).
Ausbreiten von Zeichenketten, Sets und Maps
Die Idee, das Iterator-Objekt zu überspringen und das Wachstum des Ergebnisarrays zu vermeiden, gilt gleichermaßen für das Ausbreiten anderer Standarddatentypen. Tatsächlich haben wir ähnliche schnelle Pfade für primitive Zeichenketten, für Sets und für Maps implementiert, wobei wir jedes Mal darauf achten, sie bei geändertem Iterationsverhalten zu umgehen.
In Bezug auf Sets unterstützt der schnelle Pfad nicht nur das direkte Ausbreiten eines Sets ([...set]), sondern auch das Ausbreiten seines Schlüssel-Iterators ([...set.keys()]) und seines Werte-Iterators ([...set.values()]). In unseren Mikro-Benchmarks sind diese Operationen jetzt etwa 18× schneller als zuvor.
Der schnelle Pfad für Maps ist ähnlich, unterstützt jedoch kein direktes Ausbreiten eines Maps ([...map]), da wir dies als eine ungewöhnliche Operation betrachten. Aus dem gleichen Grund unterstützt keiner der schnellen Pfade den entries()-Iterator. In unseren Mikro-Benchmarks sind diese Operationen jetzt etwa 14× schneller als zuvor.
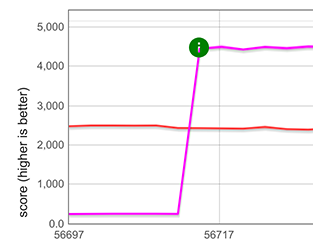
Beim Ausbreiten von Strings ([...string]) haben wir etwa eine 5× Verbesserung gemessen, wie im unten gezeigten Diagramm durch die violetten und grünen Linien dargestellt. Beachten Sie, dass dies sogar schneller ist als eine durch TurboFan optimierte for-of-Schleife (TurboFan versteht die String-Iteration und kann optimierten Code dafür generieren), dargestellt durch die blauen und pinken Linien. Der Grund für die zwei Diagramme in jedem Fall ist, dass die Mikro-Benchmarks auf zwei verschiedenen String-Repräsentationen basieren (Ein-Byte-Strings und Zwei-Byte-Strings).
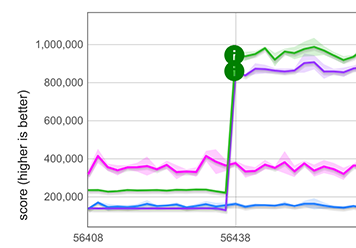
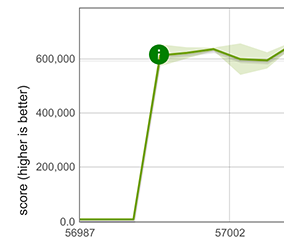
Verbesserung der Leistung von Array.from
Glücklicherweise können unsere schnellen Pfade für Spread-Elemente für Array.from wiederverwendet werden, wenn Array.from mit einem iterierbaren Objekt und ohne Mapping-Funktion aufgerufen wird, beispielsweise Array.from([1, 2, 3]). Die Wiederverwendung ist möglich, da das Verhalten von Array.from in diesem Fall genau dasselbe wie das von Spread ist. Dies führt zu einer enormen Leistungsverbesserung, die unten für ein Array mit 100 Double-Werten gezeigt wird.
Fazit
V8 v7.2 / Chrome 72 verbessert erheblich die Leistung von Spread-Elementen, wenn sie am Anfang des Array-Literal vorkommen, beispielsweise [...x] oder [...x, 1, 2]. Die Verbesserung gilt für das Ausbreiten von Arrays, primitiven Strings, Sets, Map-Schlüsseln, Map-Werten und – durch Erweiterung – für Array.from(x).