Land ahoy: Verlassen des Meer der Knoten
Der endstufige optimierende Compiler von V8, Turbofan, ist bekanntlich einer der wenigen großflächig eingesetzten Produktions-Compiler, die Sea of Nodes (SoN) verwenden. Jedoch haben wir vor fast 3 Jahren begonnen, Sea of Nodes loszuwerden und stattdessen auf eine traditionellere Control-Flow Graph (CFG) Intermediate Representation (IR) zurückzugreifen, die wir Turboshaft genannt haben. Mittlerweile nutzt der gesamte JavaScript-Backend von Turbofan Turboshaft, und WebAssembly verwendet Turboshaft in seiner gesamten Pipeline. Zwei Teile von Turbofan benutzen weiterhin Sea of Nodes: die eingebaute Pipeline, die wir langsam durch Turboshaft ersetzen, und die Frontend-Pipeline von JavaScript, die wir durch Maglev, eine weitere auf CFG basierende IR, ersetzen. In diesem Blogbeitrag erklären wir die Gründe, die uns dazu geführt haben, vom Meer der Knoten wegzugehen.
Vor 12 Jahren, im Jahr 2013, hatte V8 einen einzigen optimierenden Compiler: Crankshaft. Dieser nutzte eine Steuerflussgraphen-basierte Intermediate Representation. Die Anfangsversion von Crankshaft bot deutliche Leistungsverbesserungen, obwohl sie noch ziemlich eingeschränkt war hinsichtlich der unterstützten Funktionen. In den folgenden Jahren machte das Team kontinuierliche Fortschritte, um noch schnelleren Code in immer mehr Situationen zu generieren. Jedoch begann sich technischer Schulden aufzubauen und eine Reihe von Problemen traten bei Crankshaft auf:
-
Es enthielt zu viel handgeschriebenen Assembly-Code. Jedes Mal, wenn ein neuer Operator zur IR hinzugefügt wurde, musste seine Übersetzung in Assembly-Code für die vier offiziell von V8 unterstützten Architekturen (x64, ia32, arm, arm64) manuell geschrieben werden.
-
Es hatte Schwierigkeiten, asm.js zu optimieren, was damals als wichtiger Schritt zu leistungsstarkem JavaScript angesehen wurde.
-
Es erlaubte keine Einführung von Steuerfluss in den Absenkungen. Anders ausgedrückt: Der Steuerfluss wurde während der Graph-Erstellung bestimmt und war dann final. Dies war eine erhebliche Einschränkung, da es üblich ist, bei der Erstellung von Compilern mit höherstufigen Operationen zu beginnen und diese dann auf niedrigerstufige Operationen zu übertragen, häufig durch die Einführung zusätzlichen Steuerflusses. Betrachten wir zum Beispiel eine hochrangige Operation
JSAdd(x,y), so könnte es Sinn machen, sie später auf etwas wieif (x is String and y is String) { StringAdd(x, y) } else { … }abzusenken. Nun, das war bei Crankshaft nicht möglich. -
Try-Catches wurden nicht unterstützt, und ihre Unterstützung war äußerst herausfordernd: Mehrere Ingenieure hatten Monate damit zugebracht, sie zu implementieren, jedoch ohne Erfolg.
-
Es litt unter vielen Leistungseinbrüchen und Rückfällen. Die Nutzung einer spezifischen Funktion oder Anweisung oder das Auftreten eines spezifischen Randfalls einer Funktion konnte dazu führen, dass die Leistung um den Faktor 100 zurückging. Dadurch war es für JavaScript-Entwickler schwierig, effizienten Code zu schreiben und die Leistung ihrer Anwendungen zu antizipieren.
-
Es enthielt viele Deoptimierungsschleifen: Crankshaft optimierte eine Funktion unter Verwendung einiger spekulativer Annahmen, dann wurde die Funktion deoptimiert, wenn diese Annahmen nicht zutrafen, aber zu oft optimierte Crankshaft die Funktion erneut mit denselben Annahmen, was zu endlosen Optimierungs-Deoptimierungsschleifen führte.
Jedes dieser Probleme hätte vermutlich einzeln überwunden werden können. Doch zusammen schienen sie zu viel zu sein. Daher wurde beschlossen, Crankshaft durch einen neuen Compiler zu ersetzen, der völlig von Grund auf neu geschrieben wurde: Turbofan. Und anstatt eine traditionelle CFG IR zu verwenden, sollte Turbofan eine angeblich leistungsstärkere IR verwenden: Sea of Nodes. Zu jener Zeit war diese IR bereits seit mehr als 10 Jahren in C2, dem JIT-Compiler der Java HotSpot Virtual Machine, im Einsatz.
Aber was ist das Meer der Knoten wirklich?
Zunächst eine kleine Erinnerung an Steuerflussgraphen (CFG): Ein CFG ist eine Darstellung eines Programms als Graph, bei dem die Knoten im Graph grundlegende Blöcke (basic blocks) des Programms repräsentieren (das heißt, Abfolgen von Anweisungen ohne einkommende oder ausgehende Verzweigungen oder Sprünge), und Kanten den Steuerfluss des Programms darstellen. Hier ist ein einfaches Beispiel:

Die Anweisungen innerhalb eines grundlegenden Blocks sind implizit geordnet: Die erste Anweisung sollte vor der zweiten ausgeführt werden, die zweite vor der dritten usw. Im obigen kleinen Beispiel erscheint dies sehr natürlich: v1 == 0 kann nicht berechnet werden, bevor x % 2 berechnet wurde. Betrachten Sie jedoch

Hier scheint der CFG vorzugeben, dass a * 2 vor b * 2 berechnet wird, obwohl wir sie durchaus in umgekehrter Reihenfolge berechnen könnten.
Hier kommt das "Sea of Nodes" ins Spiel: "Sea of Nodes" repräsentiert keine grundlegenden Blöcke, sondern vielmehr nur echte Abhängigkeiten zwischen den Anweisungen. Knoten im "Sea of Nodes" sind einzelne Anweisungen (statt grundlegender Blöcke), und Kanten repräsentieren die Verwendung von Werten (Bedeutung: Eine Kante von a zu b repräsentiert die Tatsache, dass a b verwendet). So würde das letzte Beispiel mit "Sea of Nodes" dargestellt werden:

Letztendlich muss der Compiler Assemblercode generieren und diese beiden Multiplikationen nacheinander planen, aber bis dahin gibt es keine weiteren Abhängigkeiten zwischen ihnen.
Nun fügen wir Kontrollfluss hinzu. Kontrollknoten (z. B. branch, goto, return) haben normalerweise keine Wert-Abhängigkeiten zwischen sich, die eine bestimmte Reihenfolge erzwingen würden, obwohl sie definitiv in einer bestimmten Reihenfolge geplant werden müssen. Um den Kontrollfluss darzustellen, benötigen wir daher eine neue Art von Kante, Kontrollkanten, die eine Ordnung auf Knoten ohne Wert-Abhängigkeit auferlegen:

In diesem Beispiel würde ohne Kontrollkanten nichts verhindern, dass die return-Anweisungen vor der branch-Anweisung ausgeführt werden, was offensichtlich falsch wäre.
Das Entscheidende hierbei ist, dass die Kontrollkanten nur eine Reihenfolge der Operationen auferlegen, die solche eingehenden oder ausgehenden Kanten haben, nicht jedoch für andere Operationen wie die arithmetischen Operationen. Dies ist der Hauptunterschied zwischen "Sea of Nodes" und Kontrollflussgraphen.
Jetzt fügen wir wirkungsvolle Operationen (z. B. Lade- und Speicheranweisungen aus und in den Speicher) hinzu. Ähnlich wie bei Kontrollknoten haben wirkungsvolle Operationen oft keine Wert-Abhängigkeiten, können aber dennoch nicht in einer zufälligen Reihenfolge ausgeführt werden. Zum Beispiel sind a[0] += 42; x = a[0] und x = a[0]; a[0] += 42 nicht gleichwertig. Wir benötigen also eine Möglichkeit, um eine Reihenfolge (= einen Zeitplan) für wirkungsvolle Operationen vorzugeben. Wir könnten hierfür die Kontrollkette wiederverwenden, aber dies wäre strenger als erforderlich. Betrachten Sie beispielsweise diesen kleinen Ausschnitt:
let v = a[2];
if (c) {
return v;
}
Durch das Platzieren von a[2] (was Speicher liest) in der Kontrollkette würden wir es erzwingen, dass es vor dem Branch in c geschieht, obwohl diese Ladeoperation in der Praxis leicht nach dem Branch erfolgen könnte, wenn ihr Ergebnis nur innerhalb des Körpers des Then-Branches verwendet wird. Viele Knoten im Programm in der Kontrollkette zu haben, würde das Ziel von "Sea of Nodes" zunichtemachen, da wir im Grunde mit einer CFG-ähnlichen IR enden würden, bei der nur reine Operationen herumschweben.
Um mehr Freiheit zu genießen und tatsächlich von "Sea of Nodes" zu profitieren, hat Turbofan eine andere Art von Kante, Effektkanten, die eine Reihenfolge für Knoten mit Seitenwirkungen auferlegen. Lassen Sie uns den Kontrollfluss für den Moment ignorieren und uns ein kleines Beispiel ansehen:

In diesem Beispiel haben arr[0] = 42 und let x = arr[a] keine Wert-Abhängigkeit (d. h. das eine ist keine Eingabe des anderen und umgekehrt). Da jedoch a 0 sein könnte, sollte arr[0] = 42 vor x = arr[a] ausgeführt werden, damit Letzteres immer den richtigen Wert aus dem Array lädt.
Beachten Sie, dass Turbofan eine einzelne Effektkette hat (die sich an Verzweigungen teilt und wieder zusammenführt, wenn der Kontrollfluss zusammenführt), die für alle wirkungsvollen Operationen verwendet wird. Es ist jedoch möglich, mehrere Effektketten zu haben, bei denen Operationen ohne Abhängigkeiten in verschiedenen Effektketten sein könnten, wodurch deren Zeitplanung gelockert wird (siehe Kapitel 10 von SeaOfNodes/Simple für weitere Details). Wie wir später erklären werden, ist es jedoch sehr fehleranfällig, eine einzelne Effektkette aufrechtzuerhalten, sodass wir bei Turbofan nicht versucht haben, mehrere Effektketten zu implementieren.
Und natürlich enthalten die meisten echten Programme sowohl Kontrollfluss als auch wirkungsvolle Operationen.

Beachten Sie, dass store und load Kontrollinputs benötigen, da sie durch verschiedene Prüfungen (wie Typprüfungen oder Bereichsprüfungen) geschützt sein könnten.
Dieses Beispiel zeigt gut die Stärke des Sea of Nodes im Vergleich zum CFG: y = x * c wird nur im else-Zweig verwendet und kann daher frei nach dem branch schweben, anstatt wie im ursprünglichen JavaScript-Code vor dem branch berechnet zu werden. Ähnliches gilt für arr[0], das nur im else-Zweig verwendet wird und könnte daher nach dem branch schweben (obwohl Turbofan in der Praxis arr[0] nicht verschiebt, aus Gründen, die ich später erklären werde).
Zum Vergleich, hier ist, wie das entsprechende CFG aussehen würde:

Bereits hier sehen wir das Hauptproblem mit SoN: Es ist viel weiter entfernt von sowohl der Eingabe (Quellcode) als auch der Ausgabe (Maschinencode) des Compilers als CFG, was es weniger intuitiv zu verstehen macht. Zudem macht es das explizite Vorhandensein von Effekt- und Kontrollabhängigkeiten schwer, das Diagramm schnell zu verstehen und Lowerings zu schreiben (da Lowerings immer explizit die Kontroll- und Effektkette aufrechterhalten müssen, was in einem CFG implizit ist).
Und die Schwierigkeiten beginnen…
Nach mehr als einem Jahrzehnt Erfahrung mit Sea of Nodes denken wir, dass es mehr Nachteile als Vorteile hat, zumindest was JavaScript und WebAssembly betrifft. Im Folgenden werden wir einige der Probleme detaillierter betrachten.
Die manuelle/visuelle Inspektion und das Verständnis eines Sea of Nodes-Diagramms sind schwierig
Wir haben bereits gesehen, dass auf kleinen Programmen CFG leichter zu lesen ist, da es näher am ursprünglichen Quellcode liegt, den Entwickler (einschließlich Compiler-Ingenieure!) gewohnt sind zu schreiben. Für Leser, die nicht überzeugt sind, möchte ich ein etwas größeres Beispiel anbieten, damit Sie das Problem besser verstehen. Betrachten Sie die folgende JavaScript-Funktion, die ein Array von Strings konkateniert:
function concat(arr) {
let res = "";
for (let i = 0; i < arr.length; i++) {
res += arr[i];
}
return res;
}
Hier ist das entsprechende Sea of Nodes-Diagramm, in der Mitte der Turbofan-Kompilierungspipeline (was bedeutet, dass einige Lowerings bereits erfolgt sind):
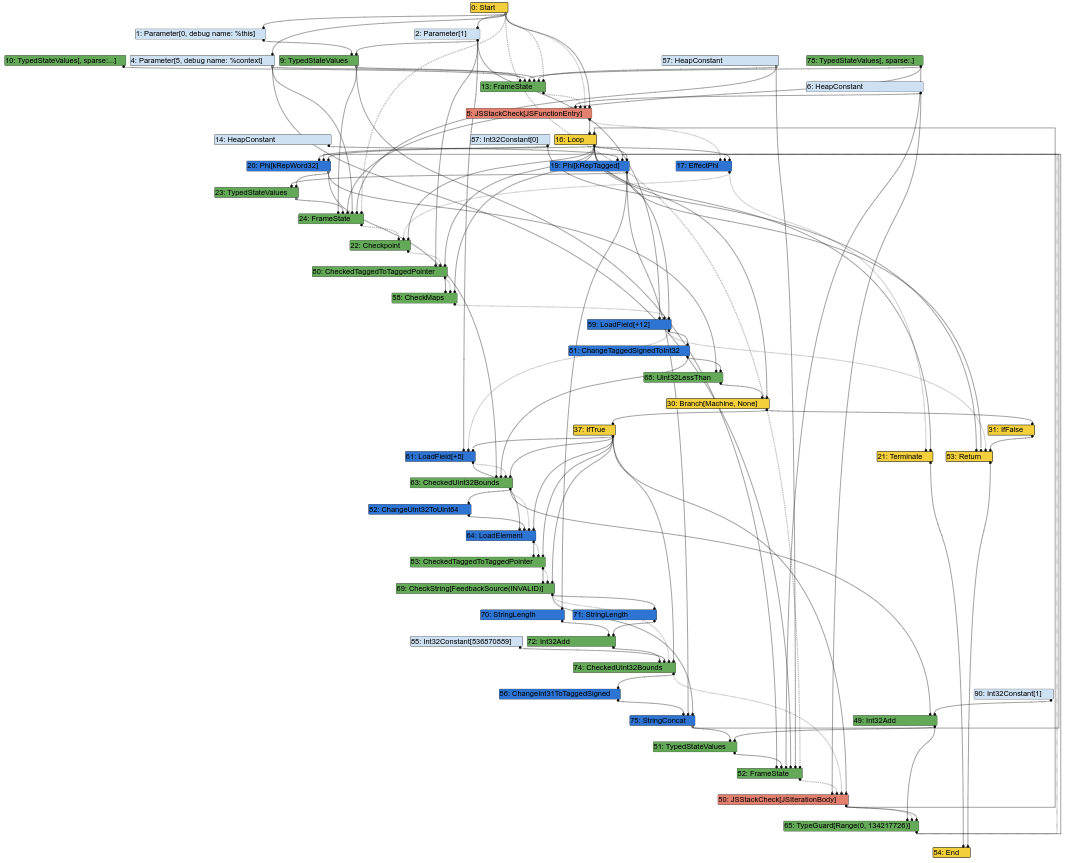
Dies sieht bereits wie ein wirres Durcheinander von Knoten aus. Und als Compiler-Ingenieur besteht ein großer Teil meiner Arbeit darin, Turbofan-Diagramme zu betrachten, um entweder Bugs zu verstehen oder Optimierungsmöglichkeiten zu finden. Nun, das ist nicht einfach, wenn das Diagramm so aussieht. Schließlich ist die Eingabe eines Compilers der Quellcode, der CFG-ähnlich ist (Anweisungen haben alle eine feste Position in einem bestimmten Block), und die Ausgabe des Compilers ist Maschinencode, der ebenfalls CFG-ähnlich ist (Anweisungen haben ebenfalls eine feste Position in einem bestimmten Block). Ein CFG-ähnliches IR zu haben, erleichtert es daher den Compiler-Ingenieuren, Elemente des IR mit dem Quellcode oder dem generierten Maschinencode abzugleichen.
Zum Vergleich, hier ist das entsprechende CFG-Diagramm (das wir verfügbar haben, weil wir bereits begonnen haben, Sea of Nodes durch CFG zu ersetzen):
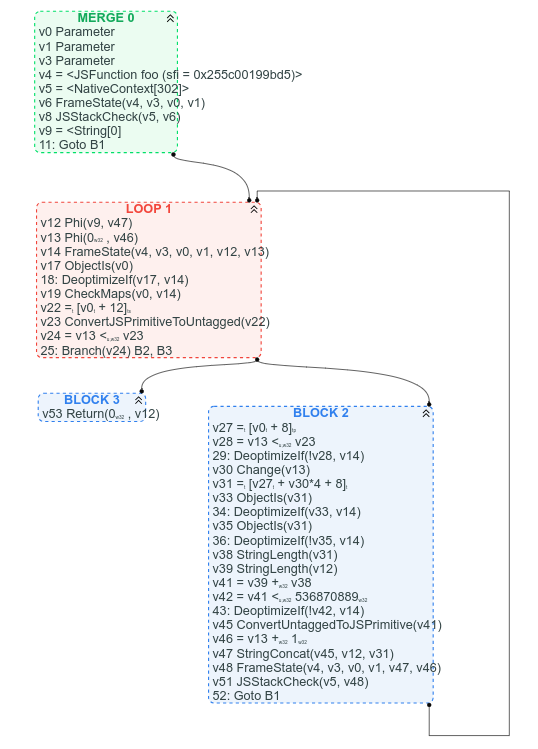
Unter anderem wird beim CFG klar, wo die Schleife ist, klar, was die Abbruchbedingung der Schleife ist, und es ist einfach, einige Anweisungen im CFG basierend auf ihren erwarteten Positionen zu finden: Zum Beispiel arr.length kann im Schleifenkopf gefunden werden (es ist v22 = [v0 + 12]), die String-Konkatenation kann gegen Ende der Schleife gefunden werden (v47 StringConcat(...)).
Man könnte argumentieren, dass die Verwendungs-Ketten der Werte im CFG schwieriger nachzuverfolgen sind, aber ich würde argumentieren, dass es in den meisten Fällen besser ist, die Kontrollflussstruktur des Diagramms klar zu sehen, anstatt ein Durcheinander von Wertknoten.
Zu viele Knoten sind in der Effektkette und/oder haben eine Kontroll-Eingabe
Um von Sea of Nodes zu profitieren, sollten die meisten Knoten im Diagramm frei schweben, ohne Kontrolle oder Effektkette. Leider ist das im typischen JavaScript-Diagramm nicht wirklich der Fall, da fast alle generischen JS-Operationen beliebige Nebeneffekte haben können. Diese sollten in Turbofan jedoch selten sein, da wir Feedback haben, das es ermöglichen sollte, sie auf spezifischere Operationen zu senken.
Dennoch benötigt jede Speicheroperation sowohl eine Effekt-Eingabe (da ein Load nicht über Stores und umgekehrt hinaus schweben sollte) als auch eine Kontroll-Eingabe (da es möglicherweise einen Typ- oder Bereichs-Check vor der Operation gibt). Und sogar einige reine Operationen wie Division benötigen Kontrolleingaben, weil sie möglicherweise Sonderfälle haben, die durch Checks geschützt werden.
Werfen wir einen Blick auf ein konkretes Beispiel und beginnen mit der folgenden JavaScript-Funktion:
function foo(a, b) {
// angenommen, `a.str` und `b.str` sind Strings
return a.str + b.str;
}
Hier ist das entsprechende Turbofan-Diagramm. Um die Dinge klarer zu machen, habe ich einen Teil der Effektkette mit gestrichelten roten Linien hervorgehoben und einige Knoten mit Zahlen annotiert, damit ich sie unten besprechen kann.
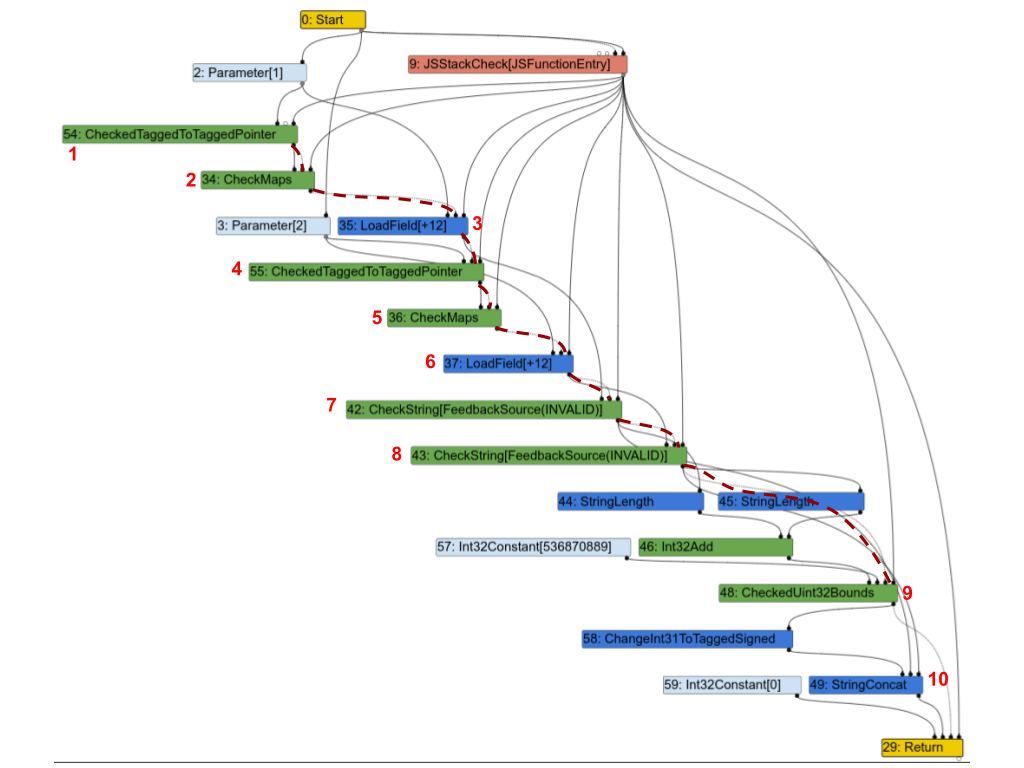
Die erste Beobachtung ist, dass fast alle Knoten in der Effektkette sind. Gehen wir über einige von ihnen hinweg und sehen, ob sie wirklich notwendig sind:
1(CheckedTaggedToTaggedPointer): Dies überprüft, dass die 1. Eingabe der Funktion ein Zeiger und keine „kleine Ganzzahl“ ist (siehe Pointer Compression in V8). Für sich genommen würde es eigentlich keinen Effekt-Eingang benötigen, aber in der Praxis muss es dennoch in der Effektkette sein, da es die folgenden Knoten schützt.2(CheckMaps): Jetzt, da wir wissen, dass die 1. Eingabe ein Zeiger ist, lädt dieser Knoten seine „Karte“ (siehe Maps (Hidden Classes) in V8) und überprüft, ob sie dem Feedback entspricht, das für dieses Objekt aufgezeichnet wurde.3(LoadField): Jetzt, da wir wissen, dass das 1. Objekt ein Zeiger mit der richtigen Karte ist, können wir sein.str-Feld laden.4,5und6sind Wiederholungen für die zweite Eingabe.7(CheckString): Jetzt, da wira.strgeladen haben, überprüft dieser Knoten, ob es tatsächlich ein String ist.8: Wiederholung für die zweite Eingabe.9: Überprüft, ob die kombinierte Länge vona.strundb.strkleiner ist als die maximale Größe eines Strings in V8.10(StringConcat): Schließlich werden die beiden Strings verkettet.
Dieser Graph ist sehr typisch für Turbofan-Graphen in JavaScript-Programmen: Karten überprüfen, Werte laden, die Karten der geladenen Werte überprüfen und so weiter, und schließlich einige Berechnungen mit diesen Werten durchführen. Und wie in diesem Beispiel enden in vielen Fällen die meisten Anweisungen in der Effekt- oder Kontrollkette, was eine strikte Reihenfolge der Operationen auferlegt und den Zweck des Sea of Nodes vollständig untergräbt.
Speicheroperationen schweben nicht leicht
Betrachten wir das folgende JavaScript-Programm:
let x = arr[0];
let y = arr[1];
if (c) {
return x;
} else {
return y;
}
Da x und y jeweils nur auf einer Seite der if-else verwendet werden, könnten wir hoffen, dass SoN es ihnen erlaubt, frei in die „then“- und „else“-Zweige zu fließen. In der Praxis ist dies jedoch in SoN nicht einfacher als in einem CFG umzusetzen. Schauen wir uns den SoN-Graphen an, um zu verstehen, warum:

Wenn wir den SoN-Graphen erstellen, erstellen wir die Effektkette in der Reihenfolge, und so landet das zweite Load direkt nach dem ersten, wonach die Effektkette sich aufteilen muss, um beide returns zu erreichen (falls Sie sich fragen, warum returns überhaupt in der Effektkette sind: Es könnte Effekte mit Nebenwirkungen wie Stores geben, die vor dem Rücksprung aus der Funktion ausgeführt werden müssen). Da das zweite Load ein Vorgänger für beide returns ist, muss es vor dem branch geplant werden, und SoN erlaubt somit keinem der beiden Loads, frei nach unten zu schweben.
Um die Loads in die „then“- und „else“-Zweige zu verschieben, müssten wir berechnen, dass dazwischen keine Seiteneffekte stattfinden und dass es zwischen dem zweiten Load und den returns ebenfalls keine Seiteneffekte gibt. Dann könnten wir die Effektkette zu Beginn und nicht erst nach dem zweiten Load teilen. Diese Analyse auf einem SoN-Graphen oder einem CFG durchzuführen, ist extrem ähnlich.
Da wir jetzt erwähnt haben, dass viele Knoten in der Effektkette enden und dass Effektknoten oft nicht sehr weit frei schweben, ist es ein guter Zeitpunkt zu erkennen, dass SoN im Grunde nur ein CFG ist, bei dem reine Knoten schweben. Tatsächlich spiegeln die Kontrollknoten und Kontrollkette in der Praxis immer die Struktur des äquivalenten CFG wider. Und wenn beide Ziele eines Zweigs Seiteneffekte haben (was in JavaScript häufig vorkommt), teilt und vereint sich die Effektkette genau dort, wo es die Kontrollkette tut (wie es im obigen Beispiel der Fall ist: Die Kontrollkette teilt sich beim branch, und die Effektkette spiegelt dies wider, indem sie sich beim Load teilt; und wenn das Programm nach dem if-else fortgesetzt würde, würden sich beide Ketten ungefähr an derselben Stelle vereinigen). Effektknoten sind somit typischerweise darauf beschränkt, zwischen zwei Kontrollknoten, d.h. in einem Basisblock, geplant zu werden. Und innerhalb dieses Basisblocks wird die Effektkette Effektknoten so einschränken, dass sie in derselben Reihenfolge auftreten wie im Quellcode. Am Ende schweben nur reine Knoten tatsächlich frei.
Eine Möglichkeit, mehr schwebende Knoten zu erhalten, besteht darin, wie zuvor erwähnt, mehrere Effektketten zu verwenden, aber dies hat seinen Preis: Erstens ist es schon schwierig, eine einzige Effektkette zu verwalten; mehrere zu verwalten, wird viel schwieriger sein. Zweitens haben wir in einer dynamischen Sprache wie JavaScript viele Speicherzugriffe, die sich überlappen könnten. Das bedeutet, dass sich die mehreren Effektketten sehr oft vereinigen müssten, was einen Teil der Vorteile von mehreren Effektketten zunichtemachen würde.
Die manuelle Verwaltung der Effekt- und Kontrollketten ist schwierig
Wie im vorherigen Abschnitt erwähnt, haben Effekt- und Kontrollkette zwar unterschiedliche Rollen, aber in der Praxis hat die Effektkette typischerweise dieselbe „Form“ wie die Kontrollkette: Wenn die Ziele eines Zweigs effektive Operationen enthalten (was oft der Fall ist), teilt sich die Effektkette im Zweig und vereinigt sich wieder, wenn der Kontrollfluss zurückkehrt. Da wir es mit JavaScript zu tun haben, haben viele Knoten Nebeneffekte, und es gibt viele Verzweigungen (typischerweise Verzweigungen basierend auf dem Typ einiger Objekte), was dazu führt, dass wir sowohl die Effektkette als auch die Kontrollkette parallel verfolgen müssen, während wir bei einem CFG nur die Kontrollkette verfolgen müssten.
Die Erfahrung zeigt, dass das manuelle Verwalten sowohl der Effekt- als auch der Kontrollkette fehleranfällig, schwer lesbar und schwer wartbar ist. Betrachten Sie diesen Beispielcode aus der JSNativeContextSpecialization-Phase:
JSNativeContextSpecialization::ReduceNamedAccess(...) {
Effekt effect{...};
[...]
Node* receiverissmi_effect = effect;
[...]
Effekt this_effect = effect;
[...]
this_effect = graph()->NewNode(common()->EffectPhi(2), this_effect,
receiverissmi_effect, this_control);
receiverissmi_effect = receiverissmi_control = nullptr;
[...]
effect = graph()->NewNode(common()->EffectPhi(control_count), ...);
[...]
}
Wegen der verschiedenen Zweige und Fälle, die hier behandelt werden müssen, verwalten wir schließlich 3 verschiedene Effektketten. Es ist leicht, etwas falsch zu machen und eine Effektkette anstelle der anderen zu verwenden. So leicht, dass wir tatsächlich anfangs einen Fehler gemacht haben und unseren Fehler erst nach einigen Monaten realisiert haben:

Bei diesem Problem würde ich sowohl Turbofan als auch Sea of Nodes die Schuld geben, anstatt nur letzterem. Bessere Helfer in Turbofan hätten die Verwaltung der Effekt- und Kontrollketten vereinfachen können, aber dieses Problem hätte in einem CFG nicht bestanden.
Der Scheduler ist zu komplex
Schließlich müssen alle Anweisungen eingeplant werden, um Assemblercode zu generieren. Die Theorie zur Planung von Anweisungen ist einfach genug: Jede Anweisung sollte nach ihren Wert-, Kontroll- und Effekt-Eingaben geplant werden (Schleifen ignorierend).
Betrachten wir ein interessantes Beispiel:

Sie werden feststellen, dass, obwohl das ursprüngliche JavaScript-Programm zwei identische Divisionen hat, das Sea of Nodes-Diagramm nur eine enthält. Tatsächlich würde Sea of Nodes mit zwei Divisionen beginnen, aber da dies eine reine Operation ist (angenommen, doppelte Eingaben), würde die Redundanzbeseitigung sie leicht in eine einzige zusammenführen.
Wenn wir dann die Planungsphase erreichen, müssten wir einen Platz finden, um diese Division zu planen. Offensichtlich kann sie nicht nach case 1 oder case 2 gehen, da sie in der anderen verwendet wird. Stattdessen müsste sie vor dem switch geplant werden. Der Nachteil ist, dass nun a / b berechnet wird, selbst wenn c 3 ist, wo es eigentlich nicht berechnet werden müsste. Dies ist ein echtes Problem, das dazu führen kann, dass viele deduplizierte Anweisungen zum gemeinsamen Dominator ihrer Benutzer schweben, wodurch viele Pfade verlangsamt werden, die sie nicht benötigen.
Es gibt jedoch eine Lösung: Der Scheduler von Turbofan wird versuchen, diese Fälle zu identifizieren und die Anweisungen so zu duplizieren, dass sie nur auf den Pfaden berechnet werden, die sie benötigen. Der Nachteil ist, dass dies den Scheduler komplexer macht und zusätzliche Logik erfordert, um herauszufinden, welche Knoten dupliziert werden könnten und sollten, und wie sie dupliziert werden.
Im Grunde genommen haben wir also mit 2 Divisionen begonnen, dann auf eine einzige Division "optimiert" und schließlich erneut auf 2 Divisionen optimiert. Und das passiert nicht nur bei Divisionen: Viele andere Operationen durchlaufen ähnliche Zyklen.
Es ist schwierig, eine gute Reihenfolge zu finden, um den Graphen zu besuchen
Alle Phasen eines Compilers müssen den Graphen besuchen, sei es, um Knoten zu reduzieren, lokale Optimierungen anzuwenden oder Analysen über den gesamten Graphen durchzuführen. In einem CFG ist die Reihenfolge, in der Knoten besucht werden, normalerweise unkompliziert: Beginnen Sie mit dem ersten Block (vorausgesetzt, eine Funktion hat einen einzigen Einstiegspunkt), und iterieren Sie durch jeden Knoten des Blocks, und gehen Sie dann zu den Nachfolgern über und so weiter. In einer Phase der Peephole-Optimierung (wie etwa Stärke-Reduktion) ist eine nette Eigenschaft der Verarbeitung des Graphen in dieser Reihenfolge, dass Eingaben immer optimiert werden, bevor ein Knoten verarbeitet wird, und das einmalige Besuchen jedes Knotens somit ausreicht, um die meisten Peephole-Optimierungen anzuwenden. Betrachten Sie zum Beispiel die folgende Abfolge von Reduktionen:

Insgesamt hat es drei Schritte gedauert, um die gesamte Abfolge zu optimieren, und jeder Schritt hat nützliche Arbeit geleistet. Danach würde die Entfernung von totem Code v1 und v2 entfernen, was dazu führt, dass eine Anweisung weniger als in der ursprünglichen Abfolge vorhanden wäre.
Mit Sea of Nodes ist es nicht möglich, reine Anweisungen von Anfang bis Ende zu verarbeiten, da sie sich in keiner Kontroll- oder Effektkette befinden und daher kein Zeiger auf reine Wurzeln oder Ähnliches vorhanden ist. Stattdessen beginnt man bei der üblichen Verarbeitung eines Sea of Nodes-Grafen für lokale Optimierungen am Ende (z. B. return-Anweisungen) und arbeitet sich über Wert-, Effekt- und Kontrolleingaben nach oben. Dies hat den Vorteil, dass keine ungenutzte Anweisung besucht wird, aber die Vorteile hören hier auch schon auf, da diese Reihenfolge für lokale Optimierungen die schlechteste Besuchsreihenfolge darstellt, die man bekommen kann. Im obigen Beispiel sind folgende Schritte erforderlich:
- Beginnen Sie mit dem Besuch von
v3, aber senken Sie es an dieser Stelle noch nicht ab, und fahren Sie dann mit seinen Eingaben fort.- Besuchen Sie
v1, senken Sie es aufa << 3ab, und fahren Sie dann mit seinen Verwendungen fort, falls die Absenkung vonv1diese optimierbar macht.- Besuchen Sie erneut
v3, aber senken Sie es noch nicht ab (diesmal würden wir seine Eingaben aber nicht erneut besuchen).
- Besuchen Sie erneut
- Besuchen Sie
v2, senken Sie es aufb << 3ab, und fahren Sie dann mit seinen Verwendungen fort, falls diese Absenkung sie optimierbar macht.- Besuchen Sie erneut
v3, senken Sie es auf(a & b) << 3ab.
- Besuchen Sie erneut
- Besuchen Sie
Insgesamt wurde v3 also 3-mal besucht, aber nur einmal abgesenkt.
Wir haben diese Auswirkung vor einiger Zeit bei typischen JavaScript-Programmen gemessen und festgestellt, dass Knoten im Durchschnitt nur einmal alle 20 Besuche geändert werden!
Eine weitere Folge der Schwierigkeit, eine gute Besuchsreihenfolge für den Grafen zu finden, ist, dass das Verfolgen von Zuständen schwierig und teuer ist. Viele Optimierungen erfordern das Verfolgen von Zuständen entlang des Grafen, wie z. B. Load Elimination oder Escape Analysis. Dies ist jedoch mit Sea of Nodes schwierig, da es zu einem bestimmten Zeitpunkt schwer zu bestimmen ist, ob ein bestimmter Zustand am Leben gehalten werden muss, da es schwierig ist zu entscheiden, ob unverarbeitete Knoten diesen Zustand zur Verarbeitung benötigen könnten. Infolge dessen hat die Load-Elimination-Phase von Turbofan bei großen Grafen einen Abbruch, um zu vermeiden, dass sie zu lange dauert und zu viel Speicher verbraucht. Zum Vergleich: Wir haben eine neue Load-Elimination-Phase für unseren neuen CFG-Compiler geschrieben, die wir im Benchmark-Test bis zu 190-mal schneller gemessen haben (sie hat eine bessere Worst-Case-Komplexität, sodass solch ein Geschwindigkeitsvorteil bei großen Grafen leicht zu erreichen ist), während erheblich weniger Speicher verwendet wird.
Cache-Unfreundlichkeit
Fast alle Phasen in Turbofan ändern den Grafen direkt vor Ort. Da Knoten im Speicher recht groß sind (meistens, weil jeder Knoten Zeiger auf sowohl seine Eingaben als auch seine Verwendungen hat), versuchen wir, Knoten so weit wie möglich wiederzuverwenden. Dennoch müssen wir zwangsläufig neue Knoten einfügen, wenn wir Knoten auf Sequenzen mehrerer Knoten absenken, die nicht unbedingt in der Nähe des ursprünglichen Knotens im Speicher allokiert werden. Infolgedessen wird der Grafen mit zunehmender Tiefe durch die Turbofan-Pipeline und je mehr Phasen wir durchlaufen, weniger cache-freundlich. Hier ist eine Illustration dieses Phänomens:

Es ist schwer, die genaue Auswirkung dieser Cache-Unfreundlichkeit auf den Speicher zu schätzen. Trotzdem können wir jetzt, da wir einen neuen CFG-Compiler haben, die Anzahl der Cache-Misses zwischen den beiden vergleichen: Sea of Nodes hat im Durchschnitt ungefähr 3-mal mehr L1-dcache-Misses im Vergleich zu unserem neuen CFG-IR und in einigen Phasen bis zu 7-mal mehr. Wir schätzen, dass dies bis zu 5% der Kompilierzeit kostet, obwohl diese Zahl etwas pauschal ist. Trotzdem ist es wichtig zu bedenken, dass in einem JIT-Compiler schnelles Kompilieren entscheidend ist.
Kontrollflussabhängige Typisierung ist begrenzt
Lassen Sie uns die folgende JavaScript-Funktion betrachten:
function foo(x) {
if (x < 42) {
return x + 1;
}
return x;
}
Wenn wir bisher nur kleine Ganzzahlen für x und für das Ergebnis von x+1 gesehen haben (wobei „kleine Ganzzahlen“ 31-Bit-Ganzzahlen sind, siehe Wert-Tagging in V8), dann spekulieren wir, dass dies so bleiben wird. Wenn wir jemals sehen, dass x größer als eine 31-Bit-Ganzzahl ist, werden wir deoptimieren. Ebenso werden wir deoptimieren, wenn x+1 ein Ergebnis liefert, das größer als 31 Bit ist. Das bedeutet, dass wir überprüfen müssen, ob x+1 weniger oder mehr als den maximalen in 31 Bit passenden Wert beträgt. Werfen wir einen Blick auf die entsprechenden CFG- und SoN-Grafen:

(angenommen, eine CheckedAdd-Operation, die ihre Eingaben addiert und deoptimiert, wenn das Ergebnis 31 Bit überläuft)
Mit einem CFG ist es leicht zu erkennen, dass, wenn CheckedAdd(v1, 1) ausgeführt wird, v1 garantiert kleiner als 42 ist und daher keine Überprüfung auf 31-Bit-Überlauf erforderlich ist. Wir würden daher die CheckedAdd-Operation leicht durch eine reguläre Add-Operation ersetzen, die schneller ausgeführt wird und keinen Deoptimierungszustand erfordert (der ansonsten benötigt wird, um zu wissen, wie die Ausführung nach der Deoptimierung fortgesetzt wird).
Mit einem SoN-Grafen hingegen fließt CheckedAdd als reine Operation frei im Grafen, und es gibt daher keine Möglichkeit, die Überprüfung zu entfernen, bis wir einen Zeitplan berechnet haben und entschieden haben, dass wir ihn nach dem Branch berechnen (und zu diesem Zeitpunkt sind wir wieder bei einem CFG, sodass dies keine SoN-Optimierung mehr ist).
Solche geprüften Operationen sind in V8 aufgrund dieser 31-Bit-Kleininteger-Optimierung häufig, und die Möglichkeit, geprüfte Operationen durch ungeprüfte Operationen zu ersetzen, kann einen erheblichen Einfluss auf die Qualität des von Turbofan generierten Codes haben. Turbofan’s SoN setzt eine Steuerungseingabe auf CheckedAdd, die diese Optimierung ermöglichen kann, bedeutet jedoch gleichzeitig die Einführung einer Planungsbeschränkung auf einen reinen Knoten, auch bekannt als die Rückkehr zu einem CFG.
Und viele andere Probleme…
Die Weitergabe der „Todesfälle“ ist schwierig. Häufig erkennen wir während einer Absenkung, dass der aktuelle Knoten tatsächlich unerreichbar ist. In einem CFG könnten wir einfach den aktuellen Grundblock hier schneiden, und die folgenden Blöcke würden automatisch offensichtlich unerreichbar werden, da sie keine Vorgänger mehr hätten. In Sea of Nodes ist dies schwieriger, da man sowohl die Kontroll- als auch die Effektkette reparieren muss. Wenn ein Knoten in der Effektkette tot ist, müssen wir die Effektkette bis zur nächsten Zusammenführung vorwärts gehen, alles entlang des Weges töten und Knoten, die sich auf der Kontrollkette befinden, sorgfältig behandeln.
Es ist schwierig, neue Kontrollflüsse einzuführen. Da Kontrollflussknoten sich in der Kontrollkette befinden müssen, ist es nicht möglich, neue Kontrollflüsse während der normalen Absenkungen einzuführen. Wenn es also einen reinen Knoten im Graphen gibt, wie beispielsweise Int32Max, der das Maximum von 2 Integer zurückgibt und den wir schließlich zu if (x > y) { x } else { y } senken möchten, ist dies in Sea of Nodes nicht einfach machbar, da wir einen Weg finden müssten, diesen Teilgraphen in der Kontrollkette anzuschließen. Eine Möglichkeit, dies umzusetzen, wäre, Int32Max von Anfang an in die Kontrollkette einzufügen, was jedoch verschwenderisch erscheint: der Knoten ist rein und sollte sich frei bewegen dürfen. Daher besteht die kanonische Methode von Sea of Nodes, wie sowohl in Turbofan als auch von Cliff Click (dem Erfinder von Sea of Nodes), in diesem Coffee Compiler Club-Chat erwähnt, darin, solche Absenkungen zu verzögern, bis wir einen Plan (und damit ein CFG) haben. Infolgedessen haben wir eine Phase in der Mitte der Pipeline, die einen Plan berechnet und den Graphen absenkt, wobei viele zufällige Optimierungen zusammengepackt werden, da sie alle einen Plan erfordern. Im Vergleich dazu könnten wir mit einem CFG diese Optimierungen früher oder später in der Pipeline durchführen.
Denken Sie auch daran, dass in der Einleitung erwähnt wurde, dass eines der Probleme von Crankshaft (dem Vorgänger von Turbofan) darin bestand, dass es praktisch unmöglich war, nach dem Aufbau des Graphen einen Kontrollfluss einzuführen. Turbofan stellt eine leichte Verbesserung gegenüber diesem dar, da das Senken von Knoten in der Kontrollkette neue Kontrollflüsse einführen kann, aber dies ist immer noch begrenzt.
Es ist schwierig herauszufinden, was sich in einer Schleife befindet. Da viele Knoten außerhalb der Kontrollkette schweben, ist es schwierig herauszufinden, was sich in jeder Schleife befindet. Infolgedessen sind grundlegende Optimierungen wie Schleifen-Peeling und Schleifen-Aufrollen schwer umzusetzen.
Kompilieren ist langsam. Dies ist eine direkte Folge mehrerer bereits erwähnter Probleme: Es ist schwierig, eine gute Besuchsreihenfolge für Knoten zu finden, was zu vielen unnötigen Wiederbesuchen führt, die Statusverfolgung ist teuer, der Speicherverbrauch ist schlecht, die Cache-Lokalität ist schlecht… Dies mag für einen Compiler mit Vorabkompilierung kein großes Problem sein, aber in einem JIT-Compiler bedeutet langsames Kompilieren, dass wir weiterhin langsamen, unoptimierten Code ausführen, bis der optimierte Code fertig ist, während Ressourcen von anderen Aufgaben (z. B. anderen Kompilierungsjobs oder dem Garbage Collector) abgezogen werden. Eine Konsequenz davon ist, dass wir gezwungen sind, sehr sorgfältig über das Kompilierungszeit-Geschwindigkeits-Verhältnis neuer Optimierungen nachzudenken, wobei wir oft eher weniger optimieren, um schnell optimieren zu können.
Sea of Nodes zerstört jede vorherige Planung durch die Konstruktion. JavaScript-Quellcode ist normalerweise nicht manuell mit Blick auf die Mikroarchitektur der CPU optimiert. WebAssembly-Code hingegen kann entweder auf Quellcodeebene (z. B. C++) oder durch eine Ahead-of-Time-(AOT)-Kompilierungs-Toolchain (wie Binaryen/Emscripten) optimiert werden. Infolgedessen könnte ein WebAssembly-Code so geplant werden, dass er auf den meisten Architekturen gut funktioniert (beispielsweise die Notwendigkeit der Auslagerung reduzieren, unter der Annahme von 16 Registern). Sea of Nodes verwirft jedoch immer die ursprüngliche Planung und verlässt sich ausschließlich auf seinen eigenen Planer, der aufgrund der Zeitbeschränkungen der JIT-Kompilierung leicht schlechter sein kann als das, was ein AOT-Compiler (oder ein C++-Entwickler, der sorgfältig über die Planung seines Codes nachdenkt) tun könnte. Wir haben Fälle gesehen, in denen WebAssembly darunter gelitten hat. Unglücklicherweise war es auch keine Option, einen CFG-Compiler für WebAssembly und einen SoN-Compiler für JavaScript in Turbofan zu verwenden, da die Verwendung desselben Compilers für beide eine Inline-Verarbeitung zwischen beiden Sprachen ermöglicht.
Sea of Nodes: elegant, aber unpraktisch für JavaScript
Um zusammenzufassen, hier sind die Hauptprobleme, die wir mit Sea of Nodes und Turbofan haben:
-
Es ist zu komplex. Wirkungs- und Kontrollketten sind schwer zu verstehen, was zu vielen subtilen Fehlern führt. Diagramme sind schwer zu lesen und zu analysieren, wodurch neue Optimierungen schwer umzusetzen und zu verfeinern sind.
-
Es ist zu begrenzt. Zu viele Knoten befinden sich in der Wirkungs- und Kontrollkette (weil wir JavaScript-Code kompilieren), was im Vergleich zu einem traditionellen Kontrollflussdiagramm nicht viele Vorteile bringt. Außerdem ist es schwierig, neuen Kontrollfluss in Reduzierungen einzuführen, was selbst grundlegende Optimierungen schwer umsetzbar macht.
-
Das Kompilieren ist zu langsam. Zustandsverfolgung ist teuer, da es schwer ist, eine gute Reihenfolge für den Besuch der Diagramme zu finden. Die Lokalisierung im Cache ist schlecht. Und das Erreichen von Fixpunkten während der Reduktionsphasen dauert zu lange.
Nach zehn Jahren mit Turbofan und dem Kampf gegen Sea of Nodes haben wir uns schließlich entschieden, es abzuschaffen und stattdessen zu einem traditionelleren Kontrollflussdiagramm-basierten IR zurückzukehren. Unsere Erfahrungen mit unserem neuen IR waren bisher äußerst positiv, und wir sind sehr glücklich, zum Kontrollflussdiagramm zurückgekehrt zu sein: Die Kompilierungszeit wurde im Vergleich zu SoN halbiert, der Code des Compilers ist wesentlich einfacher und kürzer geworden, und die Fehleruntersuchung ist in der Regel viel einfacher usw. Dieser Beitrag ist jedoch schon recht lang, deshalb höre ich hier auf. Bleiben Sie dran für einen bevorstehenden Blogbeitrag, der das Design unseres neuen Kontrollflussdiagramm-IRs namens Turboshaft erklären wird.