JavaScriptコードカバレッジ
コードカバレッジは、アプリケーションの特定部分が実行されたかどうか、必要に応じてどれくらい頻繁に実行されたかについての情報を提供します。テストスイートが特定のコードベースをどれほど徹底的に試験しているかを判断するために一般的に使用されます。
なぜ有益なのか?
JavaScript開発者として、コードカバレッジが有効な状況に直面することがよくあります。例えば以下のような場合です:
- テストスイートの品質を気にしていますか?大規模なレガシープロジェクトをリファクタリングしていますか?コードカバレッジはコードベースのどの部分がカバーされているかを正確に示します。
- コードベースの特定部分が到達されているかどうかをすぐ知りたいですか?
console.logを用いたprintf\式デバッグやコードを手動でステップ実行する代わりに、コードカバレッジはアプリケーションのどの部分が実行されたかについてライブ情報を表示できます。 - また、速度向上を目指していて注目すべき箇所を知りたい場合はどうでしょうか?実行回数がホットな関数やループを指摘できます。
V8におけるJavaScriptコードカバレッジ
今年初め、V8にネイティブJavaScriptコードカバレッジのサポートを追加しました。バージョン5.9の初期リリースでは、関数の粒度でカバレッジを提供していました(どの関数が実行されたかを示す)。その後、v6.2でブロック単位の粒度をサポートする形に拡張されました(個々の式に対しても同様)。
JavaScript開発者向け
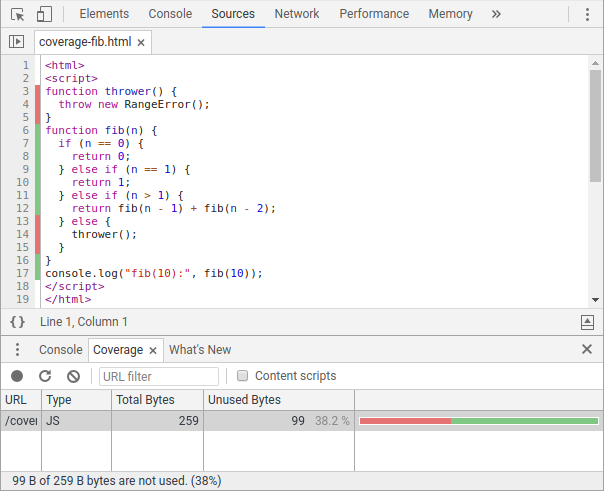
現在、カバレッジ情報にアクセスするには主に2つの方法があります。JavaScript開発者向けには、Chrome DevToolsのCoverageタブがJS(およびCSS)のカバレッジ率を公開し、Sourcesパネルで不要なコードをハイライトします。
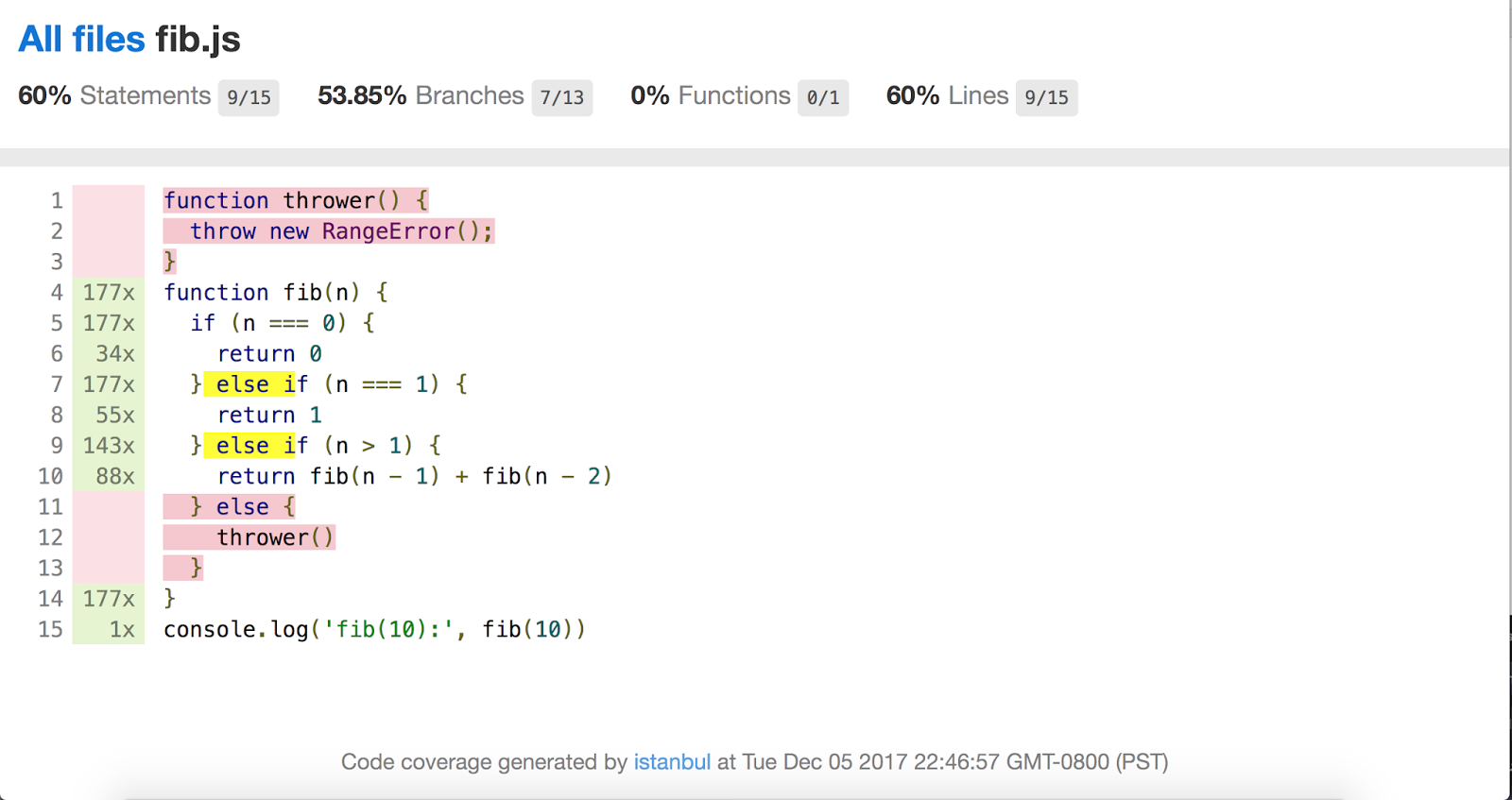
Benjamin Coe氏のおかげで、人気の最新のIstanbul.jsコードカバレッジツールにV8のコードカバレッジ情報を統合する進行中の作業も存在します。
インベッダー向け
インベッダーやフレームワーク作成者は、より柔軟な利用のためにInspector APIに直接フックすることができます。V8は2つの異なるカバレッジモードを提供します:
-
ベストエフォートカバレッジ:実行性能への影響を最小限にしながらカバレッジ情報を収集しますが、ガーベッジコレクション(GC)された関数のデータを失う可能性があります。
-
精密カバレッジ:GCによるデータ損失を防ぎ、バイナリカバレッジ情報ではなく実行回数を受け取ることを選択できます。ただし、オーバーヘッドが増加することで性能に影響が出る可能性があります(次節で詳細をご覧ください)。精密カバレッジは、関数またはブロック粒度で収集できます。
精密カバレッジ用のInspector APIは以下の通りです:
-
Profiler.startPreciseCoverage(callCount, detailed):バイナリカバレッジではなく実行回数オプション付きで、関数粒度ではなくブロック粒度オプション付きでカバレッジ収集を有効化する; -
Profiler.takePreciseCoverage():関連する実行回数とともに、収集されたカバレッジ情報をソースレンジのリストとして返す; -
Profiler.stopPreciseCoverage():収集を無効化し、関連のデータ構造を解放する。
Inspectorプロトコルによるやり取りは次のようになります:
// インベッダーがV8に対し精密カバレッジ収集を開始する指示を行います。
{ "id": 26, "method": "Profiler.startPreciseCoverage",
"params": { "callCount": false, "detailed": true }}
// インベッダーがカバレッジデータ(前回リクエスト以来の差分分)の要求を行います。
{ "id": 32, "method":"Profiler.takePreciseCoverage" }
// 応答には入れ子状のソース範囲のコレクションが含まれています。
{ "id": 32, "result": { "result": [{
"functions": [
{
"functionName": "fib",
"isBlockCoverage": true, // ブロック粒度。
"ranges": [ // 入れ子状の範囲の配列。
{
"startOffset": 50, // バイトオフセット(含む)。
"endOffset": 224, // バイトオフセット(含まない)。
"count": 1
}, {
"startOffset": 97,
"endOffset": 107,
"count": 0
}, {
"startOffset": 134,
"endOffset": 144,
"count": 0
}, {
"startOffset": 192,
"endOffset": 223,
"count": 0
},
]},
"scriptId": "199",
"url": "file:///coverage-fib.html"
}
]
}}
// 最後に、埋め込みプログラムはV8にコレクションの終了を指示し、
// 関連するデータ構造を解放します。
{"id":37,"method":"Profiler.stopPreciseCoverage"}
同様にして、ベストエフォートカバレッジは、Profiler.getBestEffortCoverage() で取得できます。
背景情報
前のセクションで述べたように、V8はコードカバレッジの2つの主要モード、ベストエフォートと精密カバレッジをサポートしています。それぞれの実装概要について以下で説明します。
ベストエフォートカバレッジ
ベストエフォートと精密カバレッジのモードはどちらもV8の他のメカニズムを大いに活用しています。最初のメカニズムは「呼び出しカウンター」と呼ばれます。V8のIgnitionインタプリタを通じて関数が呼び出されるたびに、その関数のフィードバックベクトルで呼び出しカウンターをインクリメントします。その後、関数がホットになり、最適化コンパイラを通じて層を上げると、このカウンターはインライン化する関数を決定するためのガイドとして使用されます。現在では、コードカバレッジを報告するためにも利用されます。
再利用される2番目のメカニズムは関数のソース範囲を判定することです。コードカバレッジを報告する際には、呼び出し回数をソースファイル内の関連範囲に結び付ける必要があります。たとえば、以下の例では関数fが正確に1回実行されたことだけでなく、そのソース範囲が1行目から始まり、3行目で終わることも報告する必要があります。
function f() {
console.log('こんにちは世界');
}
f();
ここでも幸運に恵まれ、V8内の既存情報を再利用することができました。Function.prototype.toStringのおかげで、関数がソースコード内の開始位置と終了位置を既に知っているため、適切な文字列部分を抽出する必要があったからです。
ベストエフォートカバレッジを収集する際には、これらの2つのメカニズムを単に結びつけます。まず、ヒープ全体をトラバースしてすべてのライブ関数を見つけます。見つかった関数ごとに、呼び出し回数(フィードバックベクトルに保存され、関数から到達可能)とソース範囲(関数自体に便利に保存されている)を報告します。
注:呼び出し回数はカバレッジが有効かどうかに関係なく維持されるため、ベストエフォートカバレッジはランタイムオーバーヘッドを増加させません。また、専用のデータ構造を使用しないため、明示的に有効化または無効化する必要もありません。
では、このモードがなぜ「ベストエフォート」と呼ばれるのか、その限界は何でしょうか?範囲外になった関数はガベージコレクターによって解放される可能性があります。これにより関連する呼び出し回数が失われ、実際にはこれらの関数が存在していたことを完全に忘れてしまいます。したがって「ベストエフォート」という名前の意味は、最善を尽くしても収集されたカバレッジ情報が不完全かもしれないことを指します。
精密カバレッジ(関数粒度)
ベストエフォートモードとは対照的に、精密カバレッジは提供されるカバレッジ情報が完全であることを保証します。これを達成するために、精密カバレッジが有効化されると、すべてのフィードバックベクトルをV8のルート参照セットに追加し、GCによる収集を防止します。これにより情報が失われることはありませんが、オブジェクトを人工的に維持するためメモリ消費が増加します。
精密カバレッジモードは実行カウントも提供できます。これは精密カバレッジ実装にさらに複雑さを加えます。覚えておくべき点は、呼び出しカウンターがV8のインタプリタを通じて関数が呼び出されるたびにインクリメントされるということです。そして、関数がホットになり最適化されると、最適化された関数はもはや呼び出しカウンターをインクリメントしません。そのため、報告された実行カウントを正確に保つには、最適化コンパイラを無効化する必要があります。
精密カバレッジ(ブロック粒度)
ブロック粒度カバレッジは、個々の式レベルまで正確なカバレッジを報告する必要があります。たとえば、以下のコードでは、ブロックカバレッジは条件付き式 : c の else ブランチが実行されていないことを検出できます。一方、関数粒度カバレッジでは関数 f(全体として)がカバーされているとしか認識できません。
function f(a) {
return a ? b : c;
}
f(true);
以前のセクションで言及した通り、V8内では関数の呼び出し回数やソース範囲がすでに利用可能でした。しかし残念ながら、ブロックカバレッジに関してはそうではなく、実行回数とそれに対応するソース範囲の収集を行う新しいメカニズムを実装する必要がありました。
最初の側面はソース範囲についてです。特定のブロックの実行回数がある場合、それをソースコードのセクションにどのようにマッピングするのでしょうか?そのためには、ソースファイルを解析する際に関連する位置を収集する必要があります。ブロックカバレッジ以前では、V8はある程度これを行っていました。一例としては、上述の通りFunction.prototype.toStringによる関数範囲の収集があります。また別の例としては、エラーオブジェクトのバックトレースを構築するためにソース位置が使用されることです。しかし、どちらもブロックカバレッジをサポートするには不十分でした。前者は関数に限定されており、後者は位置(例えばif-else文の場合のifトークンの位置など)を保存するだけで、ソース範囲は保存されません。
そのため、パーサーを拡張してソース範囲を収集する必要がありました。例として、if-else文を考えてみましょう:
if (cond) {
/* Then branch. */
} else {
/* Else branch. */
}
ブロックカバレッジが有効になっている場合、thenおよびelseブランチのソース範囲を収集し、解析されたIfStatement ASTノードに関連付けます。同様のことが他の関連する言語構造にも行われます。
解析中にソース範囲を収集した後、次の側面は実行回数をランタイムで追跡することです。これは、生成されたバイトコード配列内の戦略的な位置に新しい専用のIncBlockCounterバイトコードを挿入することで行います。ランタイム中、このIncBlockCounterバイトコードハンドラーは単純に適切なカウンターをインクリメントします(関数オブジェクトを介して到達可能)。
上記のif-else文の例では、このバイトコードは3つの場所に挿入されます:thenブランチの本体の直前、elseブランチの本体の直前、およびif-else文の直後(分岐内で非ローカルな制御が発生する可能性があるため、こうした継続カウンターが必要です)。
最後に、ブロック粒度のカバレッジ報告は関数粒度の報告と同様に動作します。しかし、フィードバックベクターからの呼び出し回数に加えて、ブロック数(関数に関連付けられた補助データ構造上に保存される)とともに_興味深い_ソース範囲の収集も報告されます。
V8内でのコードカバレッジの技術的な詳細についてさらに学びたい場合は、coverageとblock coverageのデザイン文書を参照してください。
結論
V8のネイティブコードカバレッジサポートの簡単な紹介を楽しんでいただけたことを願っています。ぜひ試してみて、何がうまくいったのか、うまくいかなかったのかを教えてください。Twitterで挨拶してください(@schuayと@hashseed)またはcrbug.com/v8/newでバグを報告してください。
V8でのカバレッジサポートはチームの努力により実現されました。貢献してくれた皆さんに感謝を述べたいと思います:Benjamin Coe、Jakob Gruber、Yang Guo、Marja Hölttä、Andrey Kosyakov、Alexey Kozyatinksiy、Ross McIlroy、Ali Sheikh、Michael Starzinger。ありがとうございました!